[논문 리뷰] EnterpriseRAG-Bench: 사내 지식 RAG 벤치마크
위키·뉴스 데이터에 치우쳐 있던 RAG 벤치마크의 한계를 지적하고, Slack·Gmail·Jira 등 9종 사내 소스를 모사한 50만 문서 규모의 합성 코퍼스와 500개 질문셋을 제안한 논문.
Series
논문 리뷰- 1AI 엔지니어 필독 논문 10개 — ① 기초 아키텍처 (Attention, VAE, GANs)
- 2AI 엔지니어 필독 논문 10개 — ② NLP 혁명과 멀티모달 (BERT, GPT, ViT, DDPM)
- 3AI 엔지니어 필독 논문 10개 — ③ 실무 적용과 학술의 속도 (RAG, LoRA, PEFT)
- 3AI 엔지니어 필독 논문 10개 — ③ 실무 적용과 학술의 속도 (RAG, LoRA, PEFT)
- 4거대 비전-언어 모델은 단 3개의 Attention Head로 충분하다
- 4[논문 리뷰] SEISMIC — Learned Sparse Retrieval을 마이크로초 단위로 끌어내리기
- 5[논문 리뷰] EnterpriseRAG-Bench: 사내 지식 RAG 벤치마크
- 6[논문 리뷰] A-RAG: Agentic RAG가 2026년의 기본기가 된 이유
- 7[논문 리뷰] Code as Agent Harness — LLM 에이전트의 계획·실행·검증 루프
- 8[논문 리뷰] Scaling Laws for Agent Harnesses — 피드백 계산으로 에이전트 성능 확장하기
- 8[논문 리뷰] DeepSeek-V4 — 1M Context에서 KV Cache 10% 수준으로 압축한 Hybrid Attention
- 9[논문 리뷰] HarnessX — 에이전트 하네스를 실행 트레이스로 진화시키기
- 9[논문 리뷰] HyperTool — 에이전트의 도구 호출 단위를 다시 설계하기
- 10[논문 리뷰] Consensus is Strategically Insufficient — 합의보다 중요한 것은 불일치의 구조다
- 11[논문 리뷰] Do Language Models Need Sleep? — 긴 컨텍스트를 잠자는 동안 정리하는 법
EnterpriseRAG-Bench: A RAG Benchmark for Company Internal Knowledge
Yuhong Sun, Joachim Rahmfeld, Chris Weaver, Roshan Desai, Wenxi Huang, Mark H. Butler (Onyx, UC Berkeley) (2026)- arXiv preprint
한 줄 요약
공개 위키·웹 데이터로 만들어진 기존 RAG 벤치마크는 사내 환경의 어수선함(약어, 중복, 오분류, 충돌하는 정보)을 전혀 담지 못한다. 저자들은 가상의 회사 "Redwood Inference"를 시뮬레이션한 약 50만 건의 문서와 10종 카테고리 500개 질문, 그리고 골드셋 자체를 보정해가는 평가 파이프라인을 제안한다.
배경 — 왜 또 다른 RAG 벤치마크인가
NQ, MS MARCO, BEIR, HotpotQA, MuSiQue, BrowseComp-Plus까지 — 검색·RAG 벤치마크는 이미 차고 넘친다. 하지만 이들은 한 가지 가정을 공유한다.
코퍼스가 위키피디아·웹·뉴스 같은 공개 자료에서 온다.
문제는 RAG가 가장 많이 쓰이는 곳이 정확히 그 반대 — 회사 내부 문서라는 점이다. 사내 데이터는 다음과 같은 특성을 가진다:
- 잡다한 채널: Slack 잡담, Gmail 스레드, Jira 티켓, Fireflies 회의록, GitHub PR 코멘트가 한 회사 안에 공존
- 사내 용어: 프로젝트 코드네임, 약어, 외부에 의미 없는 jargon
- 노이즈: 잘못된 폴더에 들어간 문서, 거의 같은 내용의 중복본, 옛 문서와 새 문서의 충돌
- 조직적 일관성: 같은 사람·프로젝트·결정이 여러 문서에 걸쳐 반복 등장
KARLBench(Databricks, 2025) 같은 시도가 있었지만, 공개된 코퍼스는 여전히 작고 대부분이 공개 문서였다. 저자들은 "공개 데이터로는 결국 못 만든다"고 보고 합성 데이터 기반 + 생성 프레임워크 공개 노선을 택했다.
핵심 아이디어
- 9종 사내 소스 × 약 50만 문서: Slack, Gmail, Linear, Google Drive, HubSpot, Fireflies, GitHub, Jira, Confluence — 실제 비율을 흉내 내어 비균등 분포로 생성.
- 10종 질문 카테고리 × 500개: 단순 검색부터 충돌 정보 해소, 정보 부재 인식까지 RAG의 다양한 실패 모드를 노린다.
- Correction-aware 평가: 골드셋을 고정 정답이 아닌 "수정 가능한 가설"로 취급하고, 3명 LLM 심판의 합의로 라벨을 갱신한다.
- 생성 프레임워크 자체를 오픈소스화 (github.com/onyx-dot-app/EnterpriseRAG-Bench). 다른 산업군이 자기 도메인에 맞춘 벤치마크를 직접 만들 수 있게.
방법론
1) 데이터셋 구성 — 회사 한 곳을 통째로 시뮬레이션
저자들은 가상의 AI 인프라 회사 "Redwood Inference"를 설정하고, 9개 소스 타입에 걸쳐 문서를 생성한다. 분포가 흥미롭다.
| 소스 | 문서 수 | 설명 |
|---|---|---|
| Slack | 275,000 | 사내 채팅 |
| Gmail | 120,000 | 이메일 스레드 |
| Linear | 35,000 | PM 티켓 |
| Google Drive | 25,000 | 공유 파일 |
| HubSpot | 15,000 | CRM 영업 기록 |
| Fireflies | 10,000 | 회의록 |
| GitHub | 8,000 | PR과 리뷰 코멘트 |
| Jira | 6,000 | 지원 티켓 |
| Confluence | 5,000 | 위키, 런북 |
Slack과 Gmail이 Confluence보다 50배 많다는 점이 핵심이다. 정돈된 위키 한 페이지당 비공식 채팅이 수십 건 존재하는 현실의 비대칭성을 그대로 옮겼다.
2) 질문 카테고리 — 실패 모드별로 설계
| # | 카테고리 | 개수 | 무엇을 시험하는가 |
|---|---|---|---|
| 1 | Basic | 175 | 키워드 겹침 있는 단순 검색 |
| 2 | Semantic | 125 | 키워드 안 겹치는 우회 표현 |
| 3 | Intra-Doc Reasoning | 40 | 한 문서 내 떨어진 부분 통합 |
| 4 | Project Related | 40 | 한 프로젝트의 여러 문서 종합 |
| 5 | Constrained | 30 | 한정자로 단일 정답 좁히기 |
| 6 | Conflicting Info | 20 | 모순된 문서 화해시키기 |
| 7 | Completeness | 20 | 관련 문서를 모두 회수 |
| 8 | Miscellaneous | 20 | 잘못된 위치의 비공식 문서 |
| 9 | High Level | 10 | 코퍼스 전반 종합 |
| 10 | Info Not Found | 20 | 답이 없음을 인식 |
10번 카테고리(Info Not Found)가 특히 영리하다. 환각을 정면으로 잡는다.
3) 생성 파이프라인 — 일관성과 비용의 균형
문서 50만 건을 매번 전체 컨텍스트와 함께 생성하면 비용이 폭발한다. 그렇다고 독립적으로 만들면 회사 내 일관성이 무너진다. 저자들은 두 갈래로 쪼갠다:
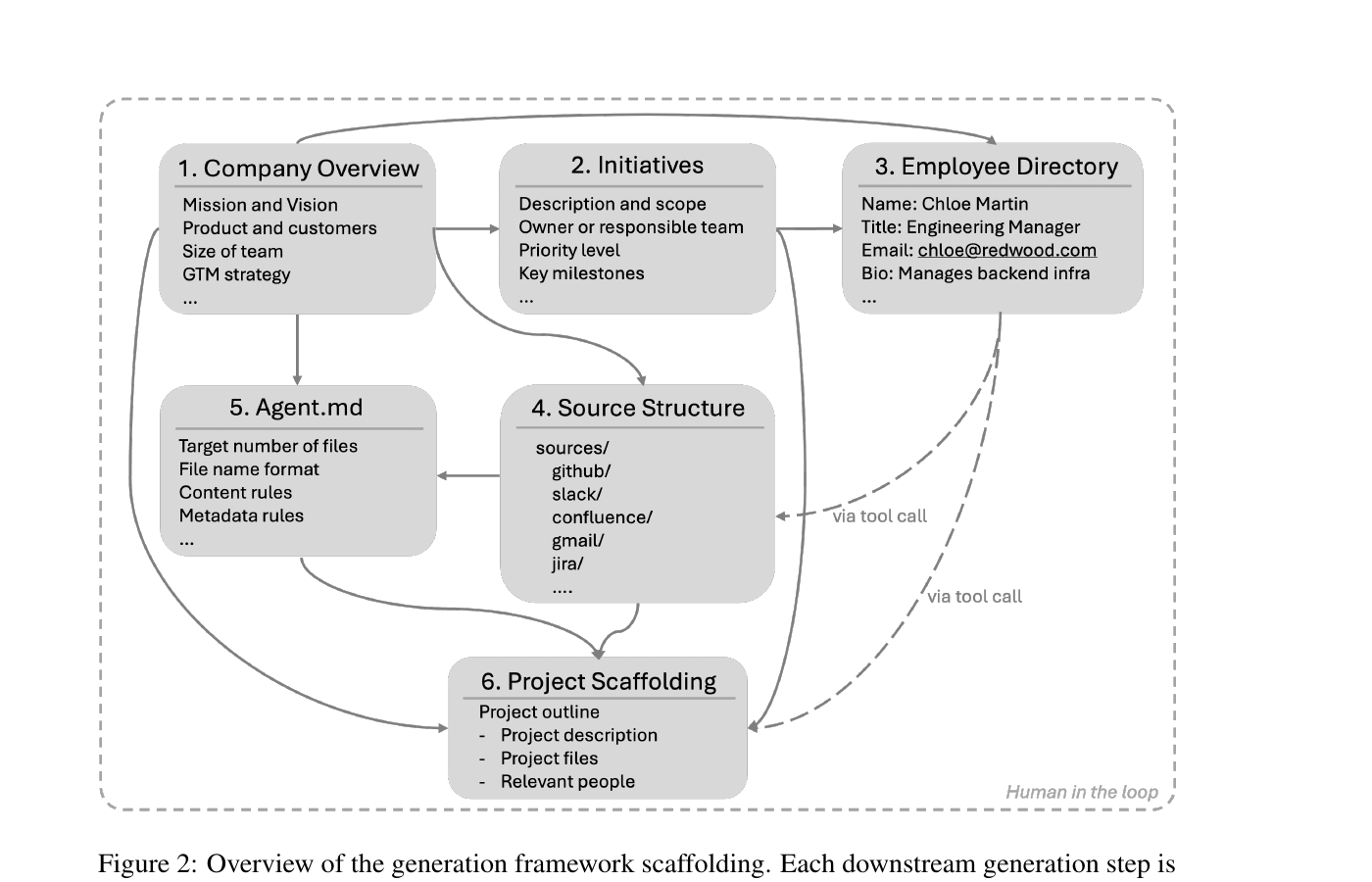
- Scaffolding — 회사 개요, 주요 이니셔티브, 직원 디렉토리, 소스 구조,
agents.md파일을 사람이 함께 만든다. 모든 후속 생성의 토대. - High-fidelity 생성 — 프로젝트 단위(약 100문서)로 풀 컨텍스트와 함께 생성. 문서 간 상호참조가 살아있다.
- High-volume 생성 — 토픽 트리로 디렉토리를 잘게 쪼갠 뒤, leaf 토픽 안에서만 생성. 좁은 컨텍스트 + 토픽 분기로 비용 절감.
논문이 솔직하게 인정하는 부분: 토픽 scaffolding 없이 "회사 개요만 주고 100개 만들어"라고 시키면 40% 이상이 거의 동일한 문서가 된다(model drift). LLM이 자기가 좋아하는 주제로 수렴하는 현상.
이후 노이즈 단계에서 4종의 인공 어수선함을 추가한다:
| 노이즈 | 메커니즘 |
|---|---|
| Random shuffle | 같은 소스 타입 내에서 무작위 재배치 (5%) |
| LLM-based shuffle | LLM이 그럴듯하게 잘못된 위치로 재배치 (3%) |
| Near-duplicates | 사실 일부를 바꾼 거의 같은 문서 (충돌 정보 질문에 사용) |
| Miscellaneous files | slack/memes, google_drive/.../misc-assets 등 비공식 디렉토리 |
4) 평가 메트릭 — 4차원 점수
각 질문은 4개 차원으로 채점한다:
- Correctness: 정답이 맞는가 (LLM 이진 판정)
- Completeness: 골드 답에 명시된 atomic facts 중 몇 %가 답변에 들어 있는가
- Document Recall@10: 골드 문서가 검색 결과에 들어 있는 비율
- Invalid Extra Documents: 골드도 valid도 아닌 잡음 문서 수 (절대값)
리더보드 점수는 단순하다 — 답이 맞으면 completeness 비율, 틀리면 0. 이를 모든 질문에 평균한다.
5) Gold Set Correction — 골드셋도 진화한다
이 논문에서 가장 신선한 부분. 50만 문서 규모에서는 골드 문서가 정말 최선인지 사람이 다 확인할 수 없다. 저자들은 평가 중 시스템이 가져온 비-골드 문서를 3명 LLM 심판이 분류하게 한다 — required / valid / invalid. 다수결로 required가 새로 발견되면 다음 릴리즈의 골드셋이 갱신된다. 단, 같은 릴리즈 내에서는 모든 제출이 동일 골드셋으로 채점되어 비교 가능성을 보장한다.
골드셋을 "고정 정답"이 아니라 "수정 가능한 가설"로 보는 관점은 LLM-judge 시대의 평가 설계에 시사하는 바가 크다.
실험 결과
베이스라인 — BM25가 의외로 강하다
세 개 베이스라인이 비교된다:
- BM25 (OpenSearch, 표준 analyzer)
- Vector search (
text-embedding-3-large, 3072 차원, Qdrant) - Bash Agent (grep, find, head 등 셸 도구로 코퍼스를 탐색하는 에이전트, 질문당 최대 10분)
답변 생성은 모두 GPT-5.4 (Medium Reasoning).
| Metric | BM25 | Vector | Bash Agent |
|---|---|---|---|
| Correctness (%) | 68.8 | 51.4 | 60.6 |
| Completeness (%) | 56.0 | 42.9 | 61.1 |
| Document Recall (%) | 68.4 | 46.0 | 55.8 |
| Invalid Extra Docs | 9.0 | 9.3 | 2.0 |
Vector search가 Semantic 카테고리에서조차 BM25에 진다 — 의미 기반 검색이 우위를 가져야 할 영역에서 정답률 32.8%, recall 24.8%로 BM25(44.8% / 43.2%)에 두 배 가까이 밀린다. 사내 약어, 코드네임, 티켓 형식이 공개 데이터로 학습된 임베딩 모델의 사각지대라는 가설을 강하게 뒷받침한다.
카테고리별 인사이트
- Bash Agent의 강점은 Completeness에 있다(61.1% vs BM25 46.5%, Vector 33.4%). 한 문서를 찾으면 인접 파일을 추가로 탐색하는 반복 발견 패턴이 "관련 문서 모두 회수" 과제에 잘 맞는다.
- Miscellaneous에서도 Bash Agent가 100% recall. 토픽 클러스터 바깥 문서를 임베딩이나 BM25는 잘 못 찾지만, 셸 탐색은 디렉토리만 알면 된다.
- 단점: 질문당 최대 10분, BM25/Vector 대비 막대한 LLM 비용.
Scaling Behavior
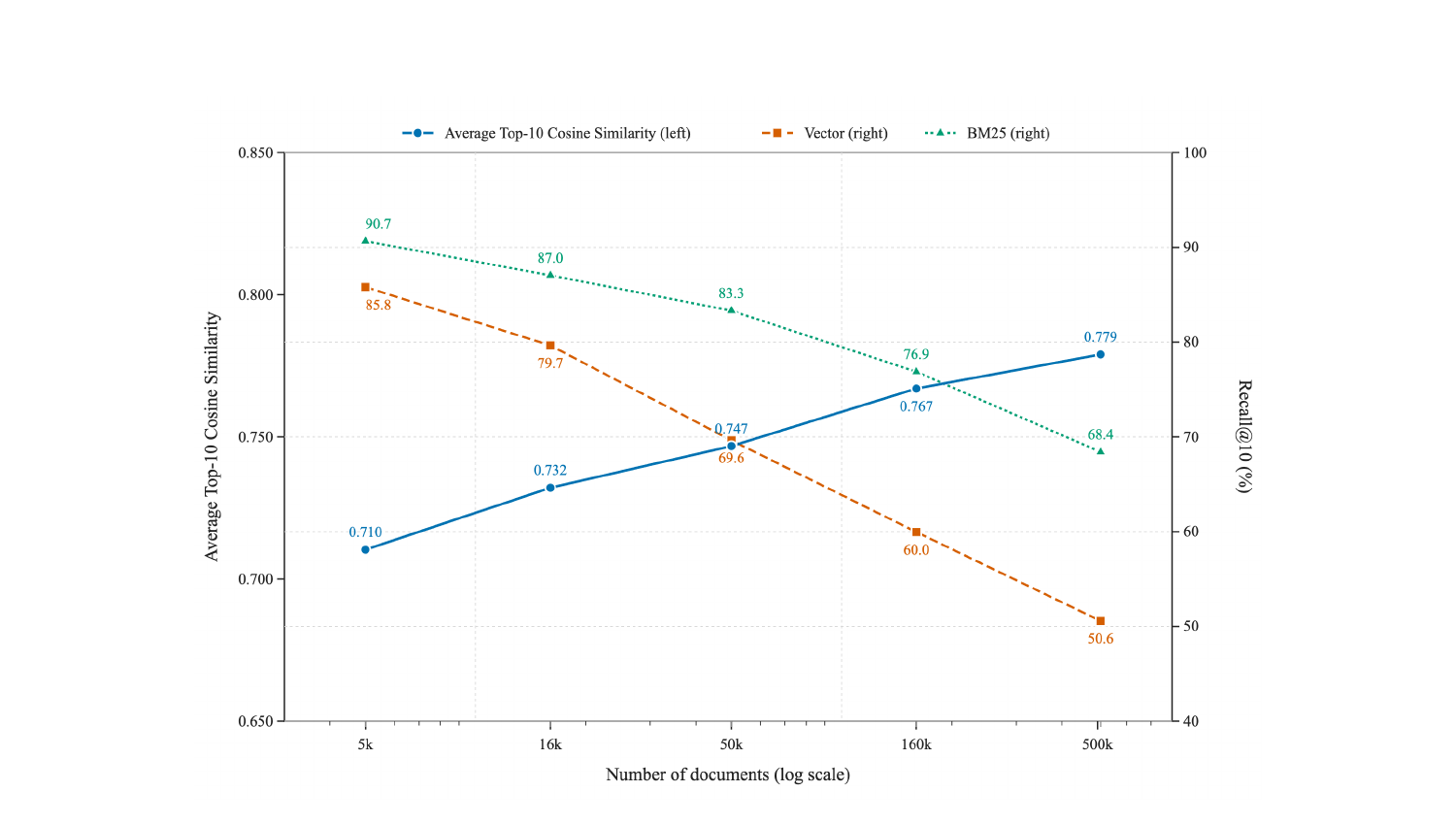
코퍼스 크기를 5k → 500k로 키우며 측정하면 — Recall@10은 BM25 90.7% → 68.4%, Vector 85.8% → 50.6%로 둘 다 떨어진다. 동시에 top-10 평균 코사인 유사도(검색 난이도의 대리 지표)는 0.71 → 0.78로 상승. 더 많은 문서가 정답 주변에 몰리며 distractor 역할을 하기 때문이다.
한계와 비판적 검토
저자들이 솔직하게 적어놓은 한계:
- 합성 데이터의 비현실성: 타임스탬프가
123456789같은 둥근 숫자로 수렴, 회사 이름이 자꾸 "ACME"로 디폴트, Slack 대화에 실제의 잡담·오해·탈선이 없음 - 표현 제약: 모든 문서를 평탄한 JSON key-value로 저장 → 이메일 인용 트리, 위키 표·이미지 등 중첩 구조 손실
- 단일 회사 시뮬레이션: 한 기술 회사의 한 시점을 가정. 산업·규모·문화 다양성 미반영
- High-volume 부분의 직원 디렉토리 미연결: 대량 생성 문서들은 가상의 직원을 인용하기도 함
내가 추가로 우려하는 점:
- GPT 계열 의존성. 생성·심판이 모두 LLM이라, 특정 모델 패밀리가 좋아하는 문체·구조가 데이터에 새겨질 수 있다. BM25가 이상하게 강한 결과도 부분적으로는 LLM이 만든 텍스트의 어휘적 일관성 때문일 수 있다.
- 한국어 환경 적용성. 코드네임·약어·jargon이라는 발상은 옮겨오기 좋지만, 한국 기업의 결재·보고·메신저 문화는 또 다른 스캐폴딩이 필요할 것이다.
- 500 질문은 적다. 카테고리당 10~175개 분포는 통계적 안정성을 흔들 수 있다. 특히 High Level은 10개뿐.
가져갈 만한 것
Correction-aware 평가가 이 논문의 가장 큰 기여라고 본다. "골드셋이 완벽하지 않다"를 결함이 아닌 설계 전제로 삼고 시스템 제출이 누적될수록 라벨이 좋아지게 만든 점은, 사내 RAG처럼 정답이 시간에 따라 바뀌는 환경에 그대로 옮겨올 만하다.
내부 평가셋을 만들 때:
- 골드셋을 변경 가능한 yaml/json으로 두고
- 3-judge 합의로 신규 후보 문서를 승격시키고
- 릴리즈 단위(예: 분기)로 라벨을 freeze 하는 방식이 현실적이다.
참고 자료
- 논문: arXiv:2605.05253
- 코드 / 데이터: github.com/onyx-dot-app/EnterpriseRAG-Bench
- 리더보드: HuggingFace Spaces
- 비교 벤치마크: BEIR, KILT, BrowseComp-Plus, KARLBench