GitHub Pages 블로그를 구글 검색에 노출시키기 (Search Console 편)
정적 블로그를 배포만 해선 구글에 안 뜬다 — Search Console 속성 등록, 소유권 확인, sitemap.xml 제출, URL 색인 요청까지 GitHub Pages + Next.js 기준으로 정리.
Series
블로그 만들기- 1정적 블로그에 댓글 시스템 도입하기 (Giscus 편)
- 2GitHub Pages 블로그를 구글 검색에 노출시키기 (Search Console 편)
- 3정적 블로그 SEO 마감하기 — OG 이미지 · RSS · JSON-LD (마감 편)
- 4블로그 만들기 4편 — 배포 자동화 (빌드 캐시 · PR 프리뷰)
이어서 — 이번엔 검색 노출
지난 편에서 댓글(Giscus)을 붙였다. 이번 편은 시리즈의 다음 관문 — 구글에 내 블로그가 검색되게 만들기다.
오해하기 쉬운데, 배포한다고 구글이 알아서 긁어가는 게 아니다. 운 좋게 어딘가에서 링크가 걸리면 언젠가 발견될 수도 있지만, 그러길 기다리는 건 전략이 아니다. 직접 "여기 사이트 있어요, 사이트맵은 이거예요" 하고 알려줘야 하고, 그 창구가 Google Search Console이다.
이 글은 https://seongyeon1.github.io (GitHub Pages, Next.js static export) 기준이다.
Vercel·Netlify·커스텀 도메인이어도 큰 흐름은 같고, 다른 부분은 그때그때 짚는다.
큰 그림 — 색인까지 4단계
구글 검색에 글 하나가 뜨기까지는 대략 이렇다.
- 발견(discovery) — 구글이 그 URL의 존재를 안다. ← 사이트맵 제출이 여기를 담당
- 크롤(crawl) — 봇이 실제로 페이지를 가져간다. ← robots.txt가 막지 않아야 함
- 색인(index) — 가져간 내용을 분석해 색인 DB에 넣는다. ← 콘텐츠 품질·중복 여부에 달림
- 노출(serving) — 검색어에 맞으면 결과에 보여준다.
Search Console은 1·2·3을 들여다보고 재촉하는 도구다. 직접 순위를 올려주진 않지만, "발견은 됐는데 색인이 안 됨" 같은 상태를 알려주고, "이 URL 지금 색인해줘"라고 요청할 수 있게 해준다. 등록 안 하면 이 과정이 전부 깜깜이로 진행된다.
사전 준비
- 배포가 끝나서
https://<당신>.github.io가 브라우저에서 열린다 - 구글 계정 하나
- (이 블로그처럼 Next.js라면)
app/sitemap.ts/app/robots.ts가 빌드 시sitemap.xml/robots.txt를 뽑고 있다
마지막 항목은 이미 이 레포에 들어가 있다. 빌드 후 out/sitemap.xml, out/robots.txt 가 생기는지 확인해두자.
1단계 — Search Console 속성 추가
search.google.com/search-console 접속 → 속성 추가. 두 가지 방식을 고르라고 한다.
| 방식 | 검증 방법 | GitHub Pages에서 |
|---|---|---|
| 도메인(Domain) | DNS TXT 레코드 | *.github.io 는 DNS를 못 건드려서 불가. 커스텀 도메인 쓸 때만 가능 |
| URL 접두어(URL prefix) | HTML 파일 / <meta> 태그 / DNS / Analytics 중 택1 | 이걸 쓴다 |
그래서 URL 접두어를 고르고, 입력란에 배포 주소를 정확히 적는다.
https://seongyeon1.github.io/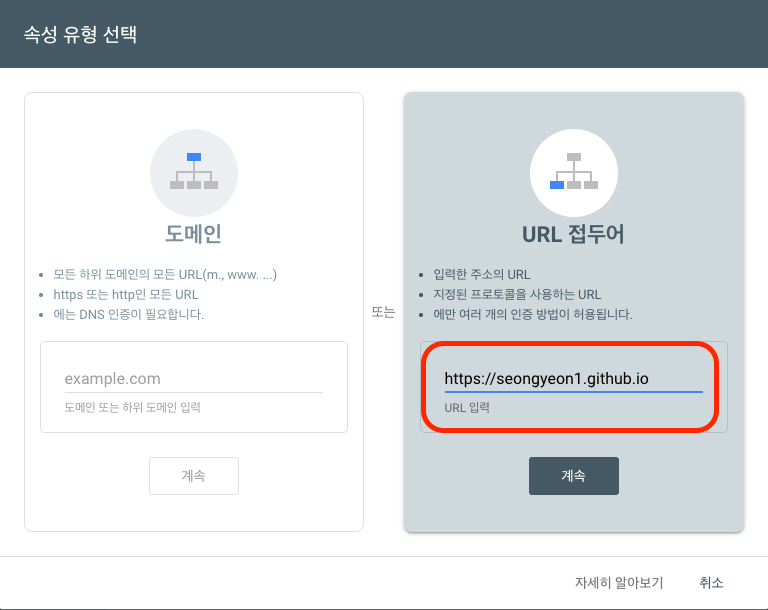
URL 접두어 속성은 스킴·호스트·경로가 정확히 일치해야 한다.
GitHub Pages는 HTTPS를 강제하므로 http:// 로 등록하면 안 되고,
www 도 붙이지 않는다. 끝의 / 는 있어도 없어도 같은 속성으로 취급된다.
2단계 — 소유권 확인
URL 접두어 속성은 보통 HTML 파일 업로드를 기본 추천한다. 정적 블로그엔 이게 가장 깔끔하다.
방법별 정리:
- HTML 파일 — 구글이 준
googleXXXX.html을 사이트 루트에 올린다. Next.js는public/에 넣으면 빌드 시 루트로 복사된다. ← 이 블로그가 쓰는 방식 <meta>태그 —<head>에<meta name="google-site-verification" ...>한 줄. Next.js라면app/layout.tsx의metadata.verification.google에 토큰만 박으면 된다.- DNS TXT — 커스텀 도메인이 있을 때. 도메인 속성과 묶어서 쓰면 깔끔.
- Google Analytics / Tag Manager — 이미 GA를 붙여놨다면 클릭 한 번.
이 블로그의 경우 — HTML 파일 방식
구글이 내려준 파일을 public/ 에 그대로 둔다.
google-site-verification: googleb788fa01b6f121d3.htmloutput: "export" 라서 빌드하면 이 파일이 out/googleb788fa01b6f121d3.html 로 복사되고,
배포 후 https://seongyeon1.github.io/googleb788fa01b6f121d3.html 로 열린다.
그 상태에서 Search Console의 확인 버튼을 누르면 끝.
확인된 뒤에도 이 파일을 지우지 말 것. 구글은 주기적으로 다시 확인하는데,
파일이 사라지면 소유권이 해제되고 데이터가 끊긴다. 그냥 레포에 박아둔다.
(<meta> 태그 방식도 마찬가지 — 한번 넣었으면 빼지 않는다.)
3단계 — sitemap.xml 과 robots.txt 점검
사이트맵은 "내 URL 목록"을 한 파일로 정리한 것이다. 손으로 쓸 필요 없이 Next.js가 만들어준다.
이 레포는 src/app/sitemap.ts 가 포스트·시리즈·태그 경로를 전부 모아 sitemap.xml 로 뽑는다.
export const dynamic = "force-static"; // static export: 빌드 타임에 sitemap.xml 로 출력
const sitemap = (): MetadataRoute.Sitemap => {
const posts = getAllPosts();
return [
{ url: `${SITE_URL}/`, changeFrequency: "weekly", priority: 1 },
...posts.map((p) => ({
url: `${SITE_URL}/blog/${p.slug}/`,
lastModified: new Date(p.date),
changeFrequency: "monthly",
priority: 0.7,
})),
// series / tags 경로도 동일하게 추가
];
};
export default sitemap;그리고 robots.txt 에 사이트맵 위치를 명시해서, 사이트맵을 일일이 제출하지 않아도 크롤러가 알아서 찾게 한다.
const robots = (): MetadataRoute.Robots => ({
rules: { userAgent: "*", allow: "/" },
sitemap: `${SITE_URL}/sitemap.xml`,
});
export default robots;trailingSlash: true 인 export 설정이면 실제 페이지 URL이 /blog/slug/ (끝에 /) 형태다.
사이트맵의 URL도 같은 형태여야 한다 — /blog/slug 와 /blog/slug/ 가 섞이면 구글이 중복으로 보고 둘 다 색인이 늦어진다.
위 sitemap.ts 는 이미 끝에 / 를 붙여서 맞춰뒀다.
배포 후 두 파일이 실제로 열리는지 확인:
https://seongyeon1.github.io/sitemap.xml
https://seongyeon1.github.io/robots.txt4단계 — Search Console에 사이트맵 제출
Search Console 좌측 메뉴 → Sitemaps → "새 사이트맵 추가"에 경로만 입력:
sitemap.xml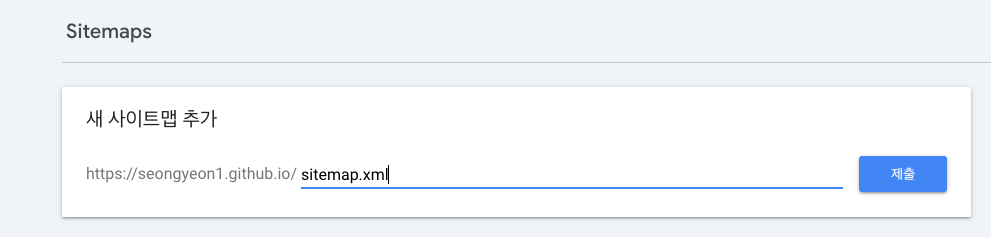
제출 직후엔 상태가 가져올 수 없음(Couldn't fetch), 발견된 페이지 0 으로 뜨는 게 정상이다 — "제출했다"는 것만 기록됐을 뿐 구글이 아직 그 파일을 안 읽은 상태다.
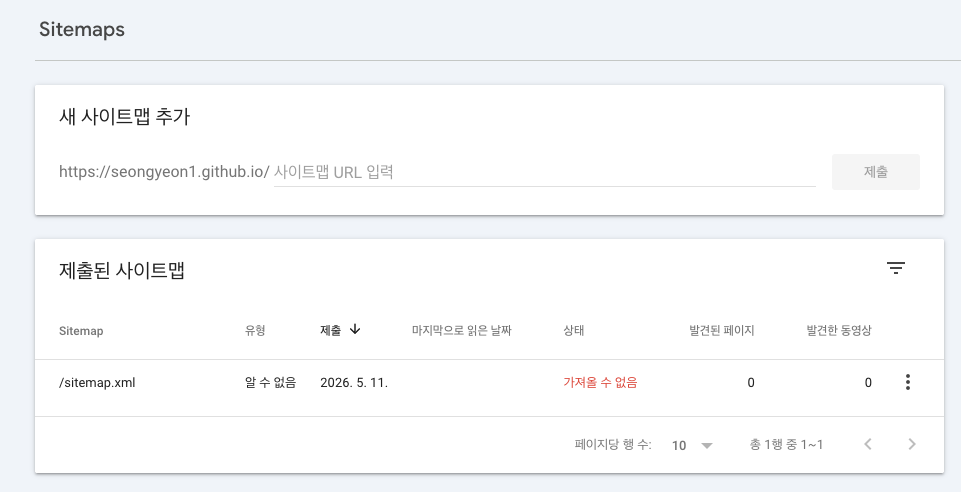
이 '가져올 수 없음' 상태는 보통 1~2일 정도 지속된다. 갓 등록한 사이트맵이라 구글의 크롤 큐에
들어가 처리되기까지 시간이 걸리는 것뿐이니, 제출만 해두고 며칠 기다리면 알아서 성공으로 바뀐다.
3일 넘게 계속 '가져올 수 없음'이면 그때 점검 — 사이트맵 URL이 실제로 열리는지(https://.../sitemap.xml 직접 접속),
경로를 전체 URL로 잘못 넣지 않았는지, 빌드 산출물에 sitemap.xml 이 실제로 포함됐는지. (아래 트러블슈팅 표 참고)
성공으로 바뀌면 "발견된 페이지 N개" 가 뜬다. N이 글 개수랑 얼추 맞으면 1단계(발견)는 통과다.
robots.txt 에 Sitemap: 줄이 있으면 구글이 알아서 찾긴 하지만, 명시적으로 제출하면
처리도 빠르고 "이 사이트맵에서 몇 개 발견/색인됐는지" 리포트가 따로 잡혀서 편하다. 둘 다 해두는 걸 추천.
5단계 — URL 검사로 색인 요청
새 글을 올렸을 때 며칠씩 기다리기 싫으면, 상단 URL 검사 창에 글 URL을 붙여넣는다.
https://seongyeon1.github.io/blog/2026-05-10-giscus-comments-setup/- "URL이 Google에 등록되어 있지 않음" → 색인 생성 요청 버튼 클릭 → 대기열에 들어간다
- "URL이 Google에 등록됨" → 이미 색인됨. 끝
- "페이지를 가져올 수 없음" 류 에러 → robots.txt 차단, 404, 리다이렉트 루프 등을 의심
요청한다고 즉시 뜨는 건 아니고, 보통 몇 시간~며칠 안에 처리된다. 하루에 요청할 수 있는 개수에 한도가 있으니, 글 쓸 때마다 한 번씩만 눌러두면 충분하다.
6단계 — 실제 노출 확인
며칠 지난 뒤 구글에서:
site:seongyeon1.github.io로 검색하면 색인된 페이지 목록이 나온다. 글 제목으로 검색해서 잡히면 완료. Search Console의 실적(Performance) 리포트에도 노출수·클릭수가 잡히기 시작한다(데이터는 2~3일 지연).
초반엔 색인이 안 된 페이지가 꽤 보인다. 페이지 색인 생성 리포트에서 "발견됨 - 현재 색인이 생성되지 않음"
상태인 URL들은 대부분 그냥 기다리면 들어온다. 단, "대체 페이지(적절한 표준 태그 포함)" 가 뜨면
canonical 설정을 점검할 것 — 이 블로그는 generateMetadata 의 alternates.canonical 로 글마다 표준 URL을 박아둬서 이 문제를 피한다.
자주 막히는 곳
| 증상 | 원인 / 해결 |
|---|---|
| 소유권 확인 실패 | 검증 파일이 루트에 없음 → public/ 에 뒀는지, 배포가 반영됐는지 확인. https://.../googleXXXX.html 직접 열어보기 |
| 확인됐다가 풀림 | 검증 파일/메타 태그를 지움 → 되돌리고 다시 확인 |
| 사이트맵 "가져올 수 없음" | 갓 제출했으면 1~2일은 정상 — 기다리면 '성공'으로 바뀜. 3일 넘게 지속되면: 빌드에 sitemap.xml 이 안 들어감 / 경로를 전체 URL로 넣음(경로만 sitemap.xml) / 사이트맵 URL이 404 |
| 발견은 됐는데 색인 0 | 갓 만든 사이트면 정상. 며칠~몇 주 소요. 급하면 URL 검사로 개별 요청 |
| 중복/표준 페이지 경고 | trailing slash 불일치, canonical 누락 → 사이트맵 URL 형식 통일 + alternates.canonical 설정 |
http:// 로 등록함 | GitHub Pages는 HTTPS 강제 → https:// 속성으로 새로 등록 |
다음 편 예고
검색 노출의 토대(속성 등록·사이트맵·색인 요청)는 깔았다. 시리즈 다음 편에선 한 단계 더 들어가서
- 글마다 OG 이미지 자동 생성 (Next.js
opengraph-image) — 공유했을 때 카드가 멀쩡하게 뜨도록 - RSS 피드 점검 (
/rss.xml) - 구조화 데이터(JSON-LD
Article) 넣어서 검색 결과 리치 스니펫 노리기
까지 다룰 예정이다.