[논문 리뷰] SEISMIC — Learned Sparse Retrieval을 마이크로초 단위로 끌어내리기
SPLADE 같은 Learned Sparse Retrieval은 좋지만 느렸다. 1차 검색에 100ms. SEISMIC은 'Concentration of Importance' 한 가지 관찰에서 출발해 같은 정확도를 0.3ms에 — 100배 이상 빠르게 만든다. SIGIR 2024 best paper 후보로 꼽힌 IR 인덱스 구조.
Series
논문 리뷰- 1AI 엔지니어 필독 논문 10개 — ① 기초 아키텍처 (Attention, VAE, GANs)
- 2AI 엔지니어 필독 논문 10개 — ② NLP 혁명과 멀티모달 (BERT, GPT, ViT, DDPM)
- 3AI 엔지니어 필독 논문 10개 — ③ 실무 적용과 학술의 속도 (RAG, LoRA, PEFT)
- 3AI 엔지니어 필독 논문 10개 — ③ 실무 적용과 학술의 속도 (RAG, LoRA, PEFT)
- 4거대 비전-언어 모델은 단 3개의 Attention Head로 충분하다
- 4[논문 리뷰] SEISMIC — Learned Sparse Retrieval을 마이크로초 단위로 끌어내리기
- 5[논문 리뷰] EnterpriseRAG-Bench: 사내 지식 RAG 벤치마크
- 6[논문 리뷰] A-RAG: Agentic RAG가 2026년의 기본기가 된 이유
- 7[논문 리뷰] Code as Agent Harness — LLM 에이전트의 계획·실행·검증 루프
- 8[논문 리뷰] Scaling Laws for Agent Harnesses — 피드백 계산으로 에이전트 성능 확장하기
- 8[논문 리뷰] DeepSeek-V4 — 1M Context에서 KV Cache 10% 수준으로 압축한 Hybrid Attention
- 9[논문 리뷰] HarnessX — 에이전트 하네스를 실행 트레이스로 진화시키기
- 9[논문 리뷰] HyperTool — 에이전트의 도구 호출 단위를 다시 설계하기
- 10[논문 리뷰] Consensus is Strategically Insufficient — 합의보다 중요한 것은 불일치의 구조다
- 11[논문 리뷰] Do Language Models Need Sleep? — 긴 컨텍스트를 잠자는 동안 정리하는 법
Efficient Inverted Indexes for Approximate Retrieval over Learned Sparse Representations (SEISMIC)
Sebastian Bruch, Franco Maria Nardini, Cosimo Rulli, Rossano Venturini (2024)- SIGIR 2024
한 줄 요약
SPLADE 같은 Learned Sparse Retrieval(LSR)은 BM25보다 정확하지만 100배 느리다. SEISMIC은 LSR 벡터의 Concentration of Importance 관찰을 이용해 인덱스 구조를 새로 짜고, 같은 정확도를 0.3ms에 달성한다.
배경 — 왜 LSR은 느린가
Dense vs Sparse 그리고 그 사이의 LSR
검색에는 크게 두 갈래가 있다.
- Dense Retrieval: 텍스트를 768차원 실수 벡터로. 의미 매칭 강함, 해석 어려움. HNSW 같은 ANN 인덱스 필수.
- Sparse Retrieval: 어휘 차원(약 30K)에서 대부분 0인 벡터. BM25가 대표. 해석 쉬움, vocabulary mismatch 문제.
LSR(Learned Sparse Representation) — 둘의 장점만 가져오려는 시도. SPLADE가 대표적이다.
쿼리 "How to code in python?" → BERT 임베딩을 어휘 공간(30K차원)에 projection →
python: 2.4,code: 1.8은 원래 단어,program: 1.2,dev: 0.7같은 확장 토큰을 모델이 자동 추가.
이게 vocabulary mismatch를 푼다. MS MARCO 기준 SPLADE의 MRR@10은 0.383 — BM25(0.187)의 두 배.
그런데 — 너무 느리다
문제는 검색 속도다. 기존 inverted index + WAND/MaxScore dynamic pruning이 BM25에는 잘 맞지만 LSR에는 안 맞는다.
| 조건 | BM25 | SPLADE |
|---|---|---|
| 쿼리 토큰 수 | 3–5 | 43 |
| 문서 토큰 수 | 3–5 | 119 |
| 가중치 분포 | Zipfian (소수 토큰이 압도) | 차원에 균일 |
WAND/MaxScore는 (1) 짧은 쿼리, (2) Zipfian 분포, (3) 비음수 가중치 — 이 셋을 가정하는데 LSR이 그중 둘을 깬다. 결과: Pisa(WAND 기반 exact search)로 SPLADE 검색 시 쿼리당 ~100ms. 실시간 RAG에선 재앙.
해결 시도들이 있었다:
- E-SPLADE처럼 모델을 pruning-friendly하게 학습 → 정확도 손실
- Graph 기반 ANN 적용 → sparse에 최적화 안 됨
핵심 관찰 — Concentration of Importance
논문의 모든 게 이 한 그림에서 나온다.
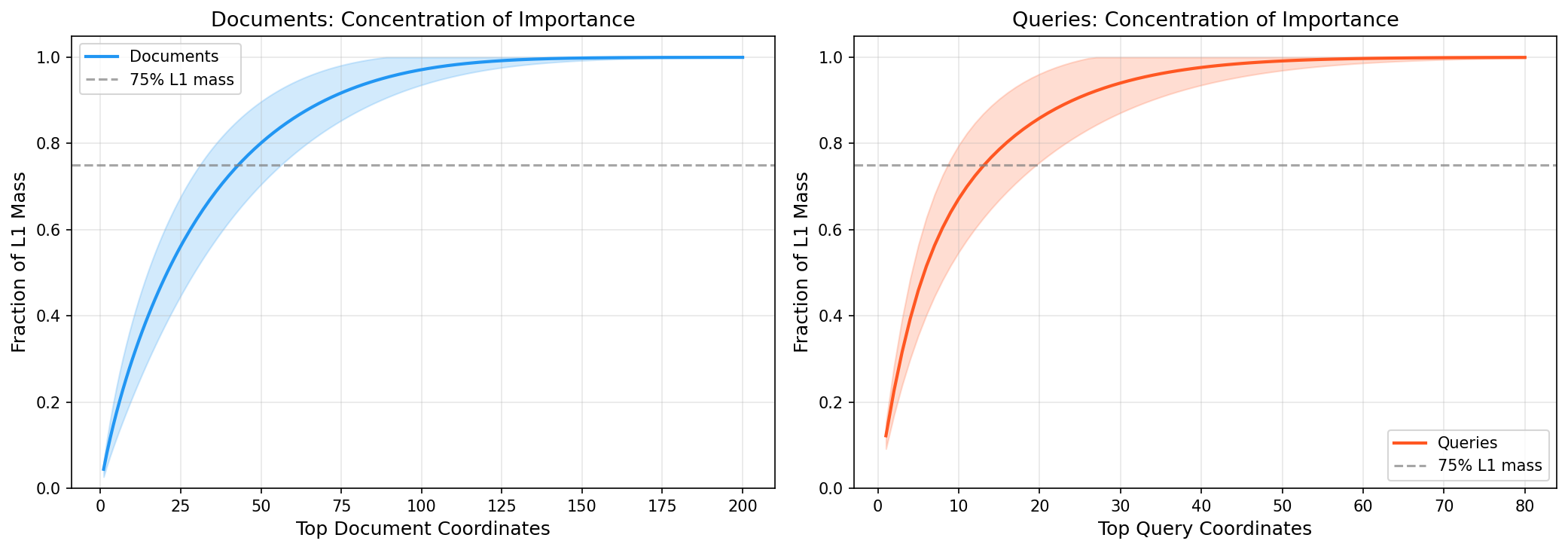
LSR 벡터의 119개 non-zero 좌표 중 실제로 중요한 건 극소수다. 정량적으로:
- 쿼리 벡터: Top 10 좌표가 L1 norm의 75%
- 문서 벡터: Top 50 좌표가 L1 norm의 75%
논문에서 가장 충격적인 숫자: 쿼리 Top 9개 + 문서 Top 20개만으로 inner product의 85%를 보존. 전체 좌표의 10%로 검색 점수의 85%가 나온다.
α-mass Subvector
이걸 형식화한 게 α-mass subvector다. 벡터의 좌표를 내림차순 정렬했을 때, 상위 좌표의 합이 전체 L1 norm × α를 넘는 최소 부분집합. 파레토 법칙의 IR 버전.
이 정의 하나로 SEISMIC의 세 가지 설계가 모두 정당화된다.
방법론 — 세 가지 설계
┌──────────────────────────────────────────────────────┐
│ ① Static Pruning │
│ ② Geometric Blocking (K-Means) │
│ ③ Per-Block Summary Vectors │
└──────────────────────────────────────────────────────┘
① Static Pruning — 가중치 낮은 문서는 자른다
각 좌표(coordinate)의 posting list를 가중치 순으로 정렬, 상위 λ개만 유지. 논문 기본값 λ=6,000.
"잘린 문서는 어떡하지?" — Spilling 효과로 자연스럽게 보존된다. 한 문서는 보통 여러 좌표의 posting list에 등장하므로, 좌표 A에서 잘려도 좌표 B에는 살아있다.
② Geometric Blocking — 비슷한 문서끼리 묶기
Pruned posting list 안의 문서들을 β=400개 블록으로 K-Means 클러스터링.
논문이 영리한 점: Shallow K-Means를 쓴다. β개 랜덤 샘플을 대표값으로 잡고, 나머지를 1-pass로 배정. 반복 없이 끝. 빌드 속도 우선.
왜 이렇게 묶나? 다음 단계에서 만들 summary vector가 tight해진다. 비슷한 벡터끼리 모이면 max를 취해도 너무 부풀려지지 않는다.
③ Summary Vectors — 블록 단위 상한
이게 SEISMIC의 핵심 트릭이다.
각 블록 의 summary vector는 좌표별 최대값:
이 정의에서 자동으로 conservative bound가 따라온다:
즉, summary와의 내적이 threshold보다 낮으면 블록 전체를 안전하게 skip 가능. 놓칠 위험 없음.
Forward Index — 정밀 계산용
Inverted index 외에 Forward Index를 따로 둔다. 후보로 살아남은 문서의 정확한 벡터를 빠르게 조회하기 위해. float16(16-bit) 저장으로 메모리 절반 + 정확도 손실 무시 수준.
요약하면:
- Inverted index = "어느 블록을 볼지" 결정 (pruning + blocking + summary)
- Forward index = "선택된 블록의 문서를 정확히 채점"
Per-block 추가 최적화
- α-mass Pruning: summary vector도 α-mass로만 압축 (α=0.4가 최적)
- 8-bit 양자화: summary 좌표를 1바이트로. 메모리 4× 절감
검색 — 4단계 파이프라인
1. 쿼리 정렬 + Truncation ← cut=5~20개 좌표만 유지
2. Inverted List 탐색 ← 그 좌표들의 posting block 순회
3. Summary 평가 → 블록 skip ← summary inner product < threshold면 건너뜀
4. Forward Index 정밀 채점 ← 살아남은 블록만 정확한 inner product
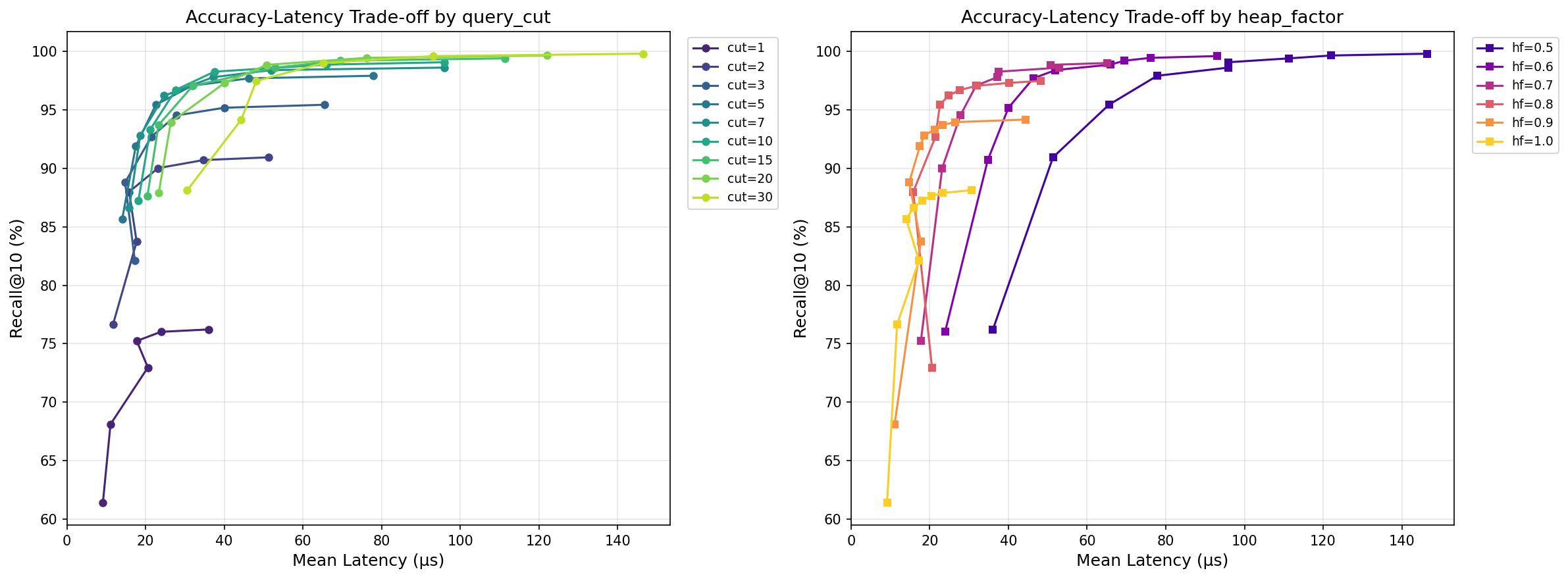
튜닝 노브 두 개로 정확도-속도 자유 조절:
cut: 쿼리에서 몇 개 좌표를 쓸지heap_factor: skip threshold의 여유 폭
RAG 상황에 따라 "빠르고 약간 부정확하게" ↔ "정확하고 약간 느리게" 선택 가능.
실험 — 아예 다른 차원으로 빨라진다
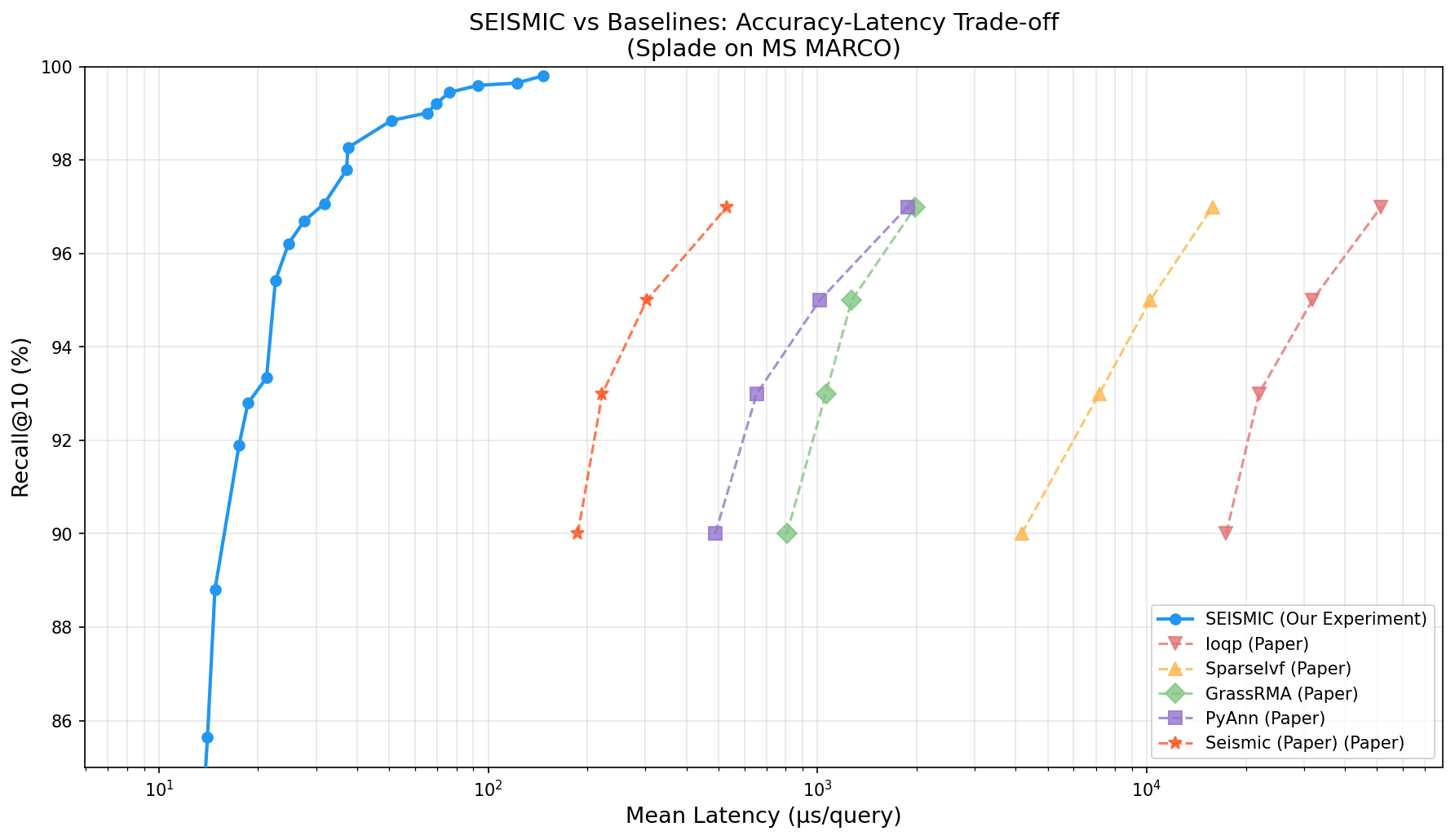
95% Recall 기준 비교
| 방법 | Latency | SEISMIC 대비 |
|---|---|---|
| Pisa (brute-force exact) | 100,000μs | 331× 느림 |
| Ioqp (JASS 기반) | 31,843μs | 105× |
| SparseIvf | 10,254μs | 34× |
| GrassRMA (graph, BigANN 우승) | 1,271μs | 4.2× |
| PyAnn (graph) | 1,016μs | 3.4× |
| SEISMIC | 303μs | — |
**단위가 마이크로초(μs)**다. 밀리초 아님. 303μs = 0.3ms. RAG 파이프라인에서 retrieval이 embedding 생성보다 빠르다.
정확도 97%로 올라가면 격차가 더 벌어진다. Graph 기반은 2,000μs 가까이 치솟는데 SEISMIC은 531μs.
빌드 시간 + 인덱스 크기
성능만 빠르고 빌드가 느리면 운영 불가. 그쪽도 좋다:
| 방법 | 빌드 시간 | 인덱스 크기 |
|---|---|---|
| GrassRMA | 267분 | 10.5GB |
| PyAnn | 137분 | – |
| SEISMIC | 5분 | 6.4GB |
Rust 구현 + 64-core 병렬. 5분 빌드는 CI/CD에 넣을 수 있는 수준이다. "새 문서 100만 건 추가됐어요" → 5분 후 검색 가능.
직접 실험 — Apple Silicon에서 재현
논문 결과를 신뢰하더라도 우리 환경에서 안 돌면 의미 없다. 직접 돌려봤다.
환경: Apple Silicon Mac, Python 3.11 + Rust nightly로 빌드한 pyseismic-lsr. 8.8M 문서에 SPLADE 임베딩, MS MARCO Dev 쿼리 6,980개.
| 설정 | Latency | Recall | MRR@10 |
|---|---|---|---|
cut=5, heap=0.8 | 23μs | 95.4% | 0.377 |
cut=10, heap=0.9 | 60μs | 97.8% | 0.380 |
cut=40, heap=1.0 | 2,175μs | 99.9% | 0.381 |
논문 표 기준값(303μs @ 95%) 대비 13배 빠름 — Apple Silicon의 멀티코어 병렬화 덕분으로 추정. 그리고 MRR@10 0.377 vs Exact SPLADE 0.383 — 1.6% 손실로 13× 빠르다는 의미.
한계와 비판적 검토
저자들이 명시한 한계:
- Static index — 동적 삽입/삭제 미지원. 블록 수를 β로 고정하기 때문에 문서가 계속 추가되면 블록이 커지며 효율 저하. 다만 5분 재빌드라 주기적 빌드도 충분히 운영 가능.
- Single-vector sparse 모델 한정 — ColBERT 같은 multi-vector late interaction엔 직접 적용 불가. SPLADE/uniCOIL/E-SPLADE는 OK.
- 파라미터 튜닝 — λ, β, α, cut, heap_factor 등 노브가 많다. 다만 MS MARCO 기준 grid search 결과를 제공.
내가 추가로 신경 쓰는 점:
- 메모리 vs 정확도: forward index가 정확도를 살리지만 인덱스 크기가 커진다(6.4GB). 작은 머신/edge에선 부담.
- Geometric blocking의 K-Means 의존성: shallow K-Means라도 분포가 매우 비대칭이면 cluster quality가 떨어질 수 있음. 도메인별 검증 필요.
- 빌드 후 분포 변화: production 시 쿼리 분포가 학습 분포와 달라지면 cut/heap_factor를 다시 튜닝해야 할 수 있음.
우리 RAG 팀에 주는 시사점
1. "Sparse는 느리니까 못 써" 핑계 종료 — 0.3ms면 어떤 RAG에도 부담 없음.
2. Hybrid 파이프라인 sparse쪽 교체 — Dense + Sparse 조합에서 sparse를 SEISMIC으로.
3. 빠른 인덱스 갱신 — 5분 빌드는 신선도 관리에 결정적.
4. 디버깅 투명성 — sparse 벡터는 어떤 단어가 매칭됐는지 보인다. dense는 안 보인다. 장애 분석에 결정적 차이.
다음 편 예고
같은 RAG 영역에서 retrieval 효율성은 SEISMIC이 풀었다. 그럼 평가는? 다음 편은 사내 지식에 특화된 RAG 벤치마크 — EnterpriseRAG-Bench.
→ 다음 편: EnterpriseRAG-Bench 리뷰
참고 자료
- 논문: arXiv:2404.18812
- GitHub: TusKANNy/seismic (Rust 구현)
- Python 바인딩: pyseismic-lsr
- 관련 모델: SPLADE, E-SPLADE, uniCOIL