[NLP] Attention 쉽게 이해하기 (Query, Key, Value, Transformer에서의 attention 3종류)
Transformer를 이해하기 위한 첫걸음으로 Attention의 직관, Q·K·V의 역할, Scaled Dot-Product Attention 수식, 그리고 Transformer 내부에 등장하는 3가지 Attention 종류를 정리한다.
Series
Attention 이해하기- 1[NLP] Attention 쉽게 이해하기 (Query, Key, Value, Transformer에서의 attention 3종류)
- 2[NLP] Transformer 3가지 Attention 자세히 보기 (Encoder/Decoder Self-Attention, Cross-Attention, Multi-Head)
- 3[NLP] Positional Encoding 이해하기 (왜 sin/cos인가?)
- 4[NLP] Layer Normalization & Residual Connection — Transformer를 깊게 쌓는 비결 (Pre-LN vs Post-LN)
- 5[NLP] Feed-Forward Network — Transformer의 숨은 표현력 (FFN, GELU, SwiGLU, MoE)
한 줄 요약 — Attention은 "한 단어가 문장 안의 다른 단어들 중 어디에 집중할지"를 확률 분포로 결정하는 메커니즘이다. Q/K/V는 그 분포를 만들기 위한 역할 분담이고, Transformer는 이 메커니즘을 세 가지 방식으로 변주해서 사용한다.
학습 내용
- Transformer를 이해하기 위한 사전 지식으로 Attention의 개념을 잡는다.
- 가장 기본적인 Attention(Q, K, V)을 직관과 수식 양쪽으로 이해한다.
- Transformer 내부에서 Attention이 어떻게 3가지로 변형되어 쓰이는지 살펴본다.
Attention
기존 RNN/LSTM 계열은 시퀀스를 한 토큰씩 순차적으로 처리하기 때문에 멀리 떨어진 토큰 간의 관계가 희미해지고, 병렬화도 어렵다는 한계가 있다. Attention은 이 문제를 단순한 아이디어로 해결한다 — "한 토큰을 처리할 때, 같은 문장의 다른 모든 토큰을 한꺼번에 보고, 그 중 의미적으로 관련 깊은 토큰에 더 집중하자."
즉, 한 문장 데이터 안에서 토큰들의 상관관계를 파악해서, 이를 통해 다음 토큰을 예측할 때(나는 → 다음단어) 유사도가 높은 단어에 가중치를 더 주자는 개념이다.
Query, Key, Value — 데이터베이스로 비유하기
Q/K/V는 데이터베이스 lookup에 비유하면 한결 명확해진다.
- Query (Q): 내가 찾고 싶은 정보. "이 단어와 다른 단어들의 상관관계를 알려줘!" 라는 질문에 해당.
- Key (K): 비교 기준이 되는 인덱스. 각 토큰이 "나는 이런 토큰이야"라고 자신을 식별하는 태그.
- Value (V): 실제로 가져올 내용. Q-K 매칭이 성공했을 때 결과로 반영되는 값.
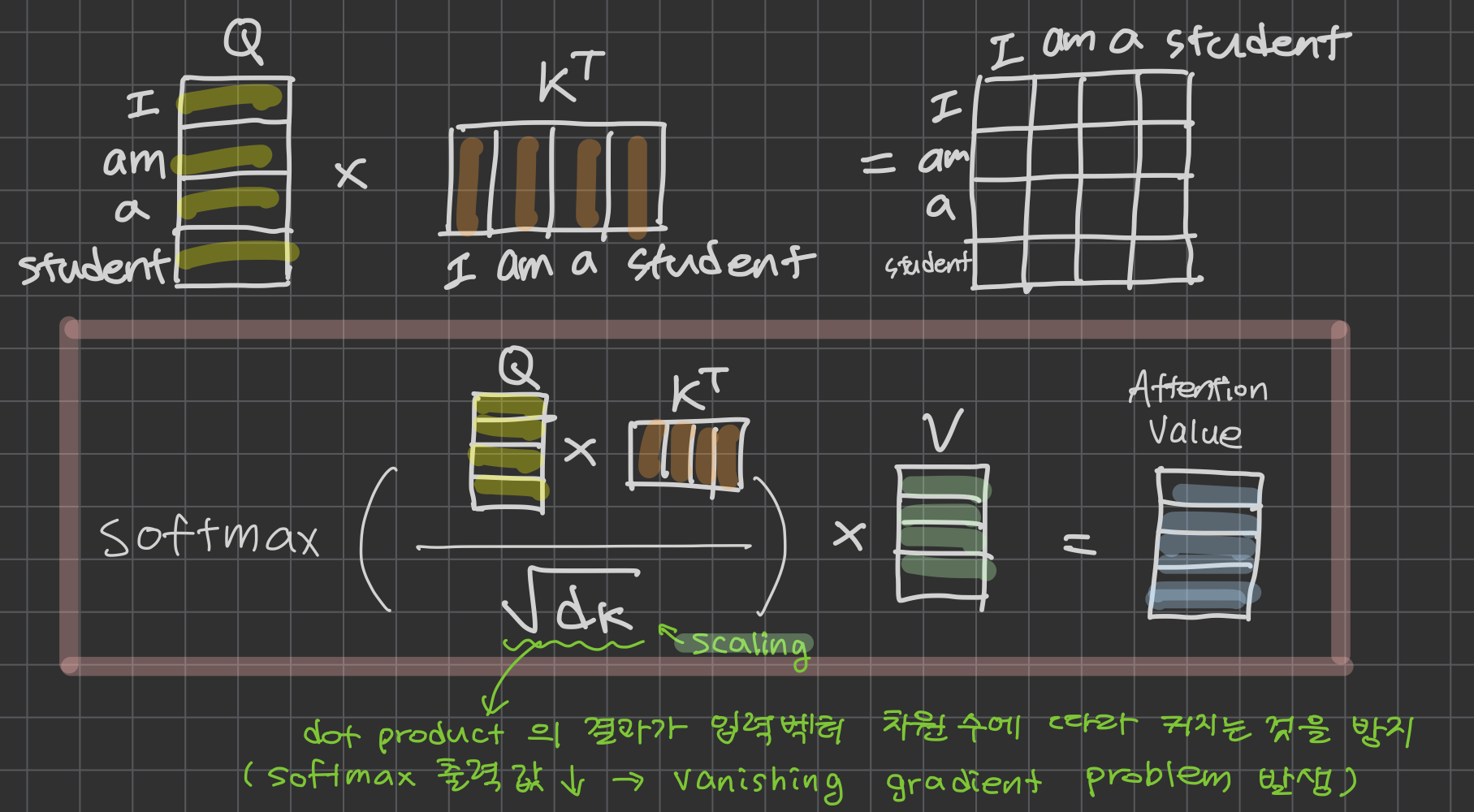
쿼리(Q)와 모든 키(K)의 유사도를 계산한 뒤, 그 유사도를 가중치로 삼아 값(V)들을 가중합 한 결과가 한 토큰의 Attention Value다.
왜 굳이 K와 V를 분리할까? 검색 키워드(K)와 검색해서 가져올 내용(V)이 항상 같지는 않기 때문이다. 분리해 두면 "어디에 집중할지" 는 K로 결정하고, "그 자리에서 무엇을 꺼낼지" 는 V로 학습할 수 있다.
Attention 계산 절차
결국 한 단어가 어떤 다른 단어에 "focus" 하는지 알아보기 위해서는 attention value가 필요하고, 이를 구하는 과정은 아래와 같다.
- 주어진 Query에 대해 모든 Key와의 유사도(dot product) 를 각각 구한다.
- 이 유사도를 softmax에 통과시켜 합이 1인 확률 분포로 만든다.
- 이 확률을 가중치로 삼아 각 Key와 매핑된 Value들을 가중합한다 → Attention Value.
Transformer에서의 Attention
Transformer가 사용하는 Scaled Dot-Product Attention의 수식은 다음과 같다.
각 부분을 풀어보면:
- : 모든 Query × 모든 Key의 dot product → 유사도 행렬
- 로 나누기 : Key 차원 가 커질수록 dot product 분산이 커져 softmax가 한쪽으로 쏠리는(saturated) 문제를 보정하는 스케일링 항
- : 유사도를 0~1 사이의 가중치 분포로 변환
- 마지막에 를 곱함 : 각 토큰의 Value를 가중치만큼 섞어 최종 표현 생성
왜 하필 인가? 두 랜덤 벡터의 dot product 분산은 차원 수에 비례한다. 가 64만 되어도 분산이 그만큼 커지기 때문에, 표준편차로 나눠서 분산을 1 근처로 맞추려는 의도다. 원 논문 Attention Is All You Need에서는 이 스케일링을 생략하면 학습이 불안정해진다고 보고한다.
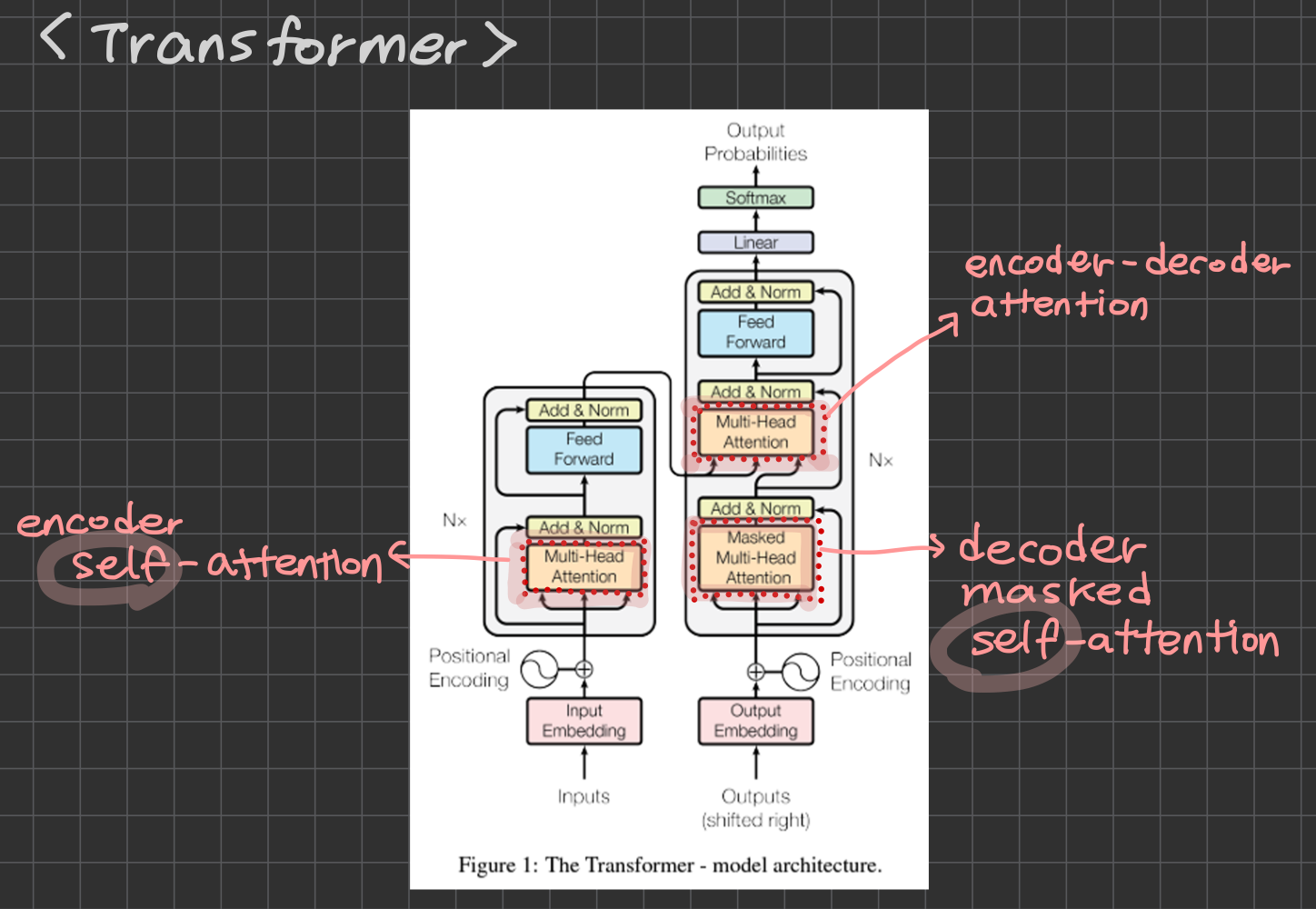
Transformer 내부의 3개의 Attention
Transformer 내부에는
- encoder self-attention
- decoder masked self-attention
- encoder-decoder attention
이렇게 3개의 attention이 등장한다. 수식은 모두 같지만 Q/K/V를 어디서 가져오느냐가 다르고, 그에 따라 의미가 달라진다.
| 종류 | Q 출처 | K, V 출처 | 역할 |
|---|---|---|---|
| Encoder Self-Attention | 입력 문장 | 입력 문장 | 입력 토큰들끼리의 상관관계 학습 |
| Decoder Masked Self-Attention | 출력(생성 중) | 출력(생성 중) | 미래 토큰을 마스킹, 과거 토큰만 참조 |
| Encoder-Decoder Attention | 디코더 | 인코더 | 디코더가 인코더 출력의 어디에 집중할지 결정 (번역의 핵심) |
같은 메커니즘을 Q와 K/V의 출처만 바꿔서 세 가지 의미로 활용하는 것이 Transformer 설계의 핵심 아이디어다.
각 Attention의 동작 방식과 Multi-Head Attention 구조는 다음 포스트에서 자세히 다룰 예정이다.
마무리
- Attention = 한 문장 안에서 누구에게 얼마나 집중할지를 학습 가능한 방식으로 결정하는 모듈
- Q/K/V = 검색(Query) · 인덱스(Key) · 실제값(Value)의 역할 분담
- Scaled Dot-Product Attention = dot product 유사도 → 스케일링 → softmax → V 가중합
- Transformer = 같은 Attention 식을 Q와 K/V의 출처를 바꿔가며 3가지 방식으로 활용